I was fascinated by the idea behind Machine Teaching ever since I was introduced to it in The Teaching Dimension of Linear Learners (JMLR-2016) by Liu, et al. Machine teaching is the inverse problem of machine learning. In machine learning, we are given a set of training examples and the goal is to design a model that accurately “learns” the target concept. In machine teaching, the objective is to design an optimal set of training examples (e.g. smallest size) to accurately “teach” the target concept to a given learning model.
Our paper takes inspiration from two ideas; teaching a single learner in the online setting introduced in Iterative Machine Teaching (ICML-2017) by Liu, et al, and the complexity of simultaneously teaching multiple learners in the offline setting studied in No Learner Left Behind (IJCAI-2017) by Zhu, et al. We focus on simultaneously teaching a classroom of diverse learners in the online setting. More specifically, we (i) design new, state-of-the-art teaching algorithms with provable guarantees under complete and incomplete information paradigms, (ii) discuss classroom partitioning strategies for improved teaching and learning experiences, and (iii) experimentally evaluate the performance of our algorithms on simulated and real-world data.
The Model
Our model consists of the following elements.
Parameters: The feature space of training examples, the label set (discrete or continuous depending on classification or regression), and the feasible hypothesis space including the target hypothesis comprise our primary parameters.
Classroom: The classroom is a set of online projected stochastic gradient descent learners. Each learner is defined by two internal parameters, a time-varying learning rate, and a time-varying internal state.
Teacher: The teacher is characterized by the amount of information she has about the students in the classroom. Knowledge represents information regarding the learning rates of the students and Observability represents information about the internal states.
Teaching Objective: We consider two objectives, either to ensure that every student in the classroom converges to the target concept or to ensure that the entire classroom on average converges to the target concept, as quickly as possible.
We consider different scenarios wherein the teacher has complete information about all the parameters and perfect Knowledge and Observability, or limited Knowledge and perfect Observability, or perfect Knowledge and limited Observability. In each of the scenarios, the model functions over a series of interactions between the teacher and the classroom. At every interaction (or time-step), the teacher receives updated information about the classroom (as defined by the scenario in question). She then chooses a training example and the corresponding label from the feature space and label set respectively, and provides it to the classroom. Lastly, each student in the classroom performs a gradient update step. This cycle repeats until the teaching objective is achieved.
The core idea of our algorithms is the training example construction step. The trick is to pick that example at every time step which minimizes the average distance between students’ internal states and the target concept. This translates to solving an optimization task. In general, this is a non-convex problem, but in the case of learners following a squared-loss function, we present a closed-form solution. For each of the scenarios, we also provide theoretical guarantees for the number of examples or iterations the teacher requires to teach the target concept.
Classroom Partitioning
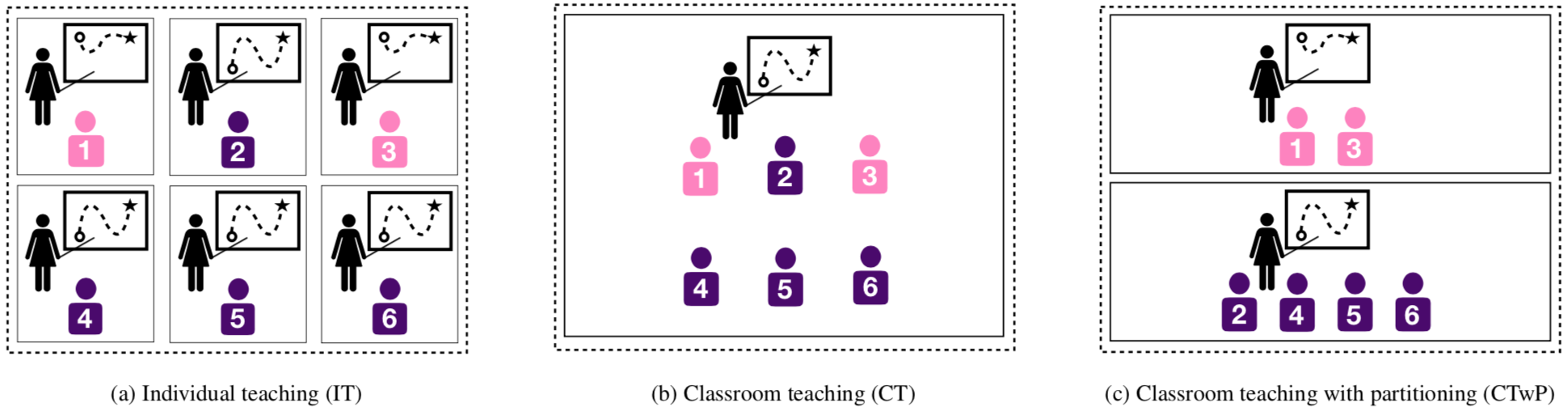
Individual teaching, the notion of teaching one student at a time, is extremely useful for the individual student because she receives personalised training. However, it is extremely cumbersome for the teacher because she has to expend extra effort in producing these personalised resources. On the other hand, having a large classroom of diverse students reduces the teacher’s effort while increasing the workload on the students. A well-studied solution from pedagogical research is to partition the classroom into smaller groups. However, there isn’t a consensus on the optimal partitioning strategy.
Figure 1: Teaching Paradigms
We propose two straightforward strategies for homogenous partitioning that follow from our model setting. The first is grouping based on learning rates of students and the second is group based on internal states. The first idea is helpful because faster learners can quickly converge to the target concept whereas slower learners would require more samples. Placing the fast learner in the same group as a slow learner adds unnecessary extra effort on the fast learner. The second idea is helpful because it groups similar kinds of students together. See the next section for a more concrete example of this.
Experiment: Classifying Butterflies and Moths
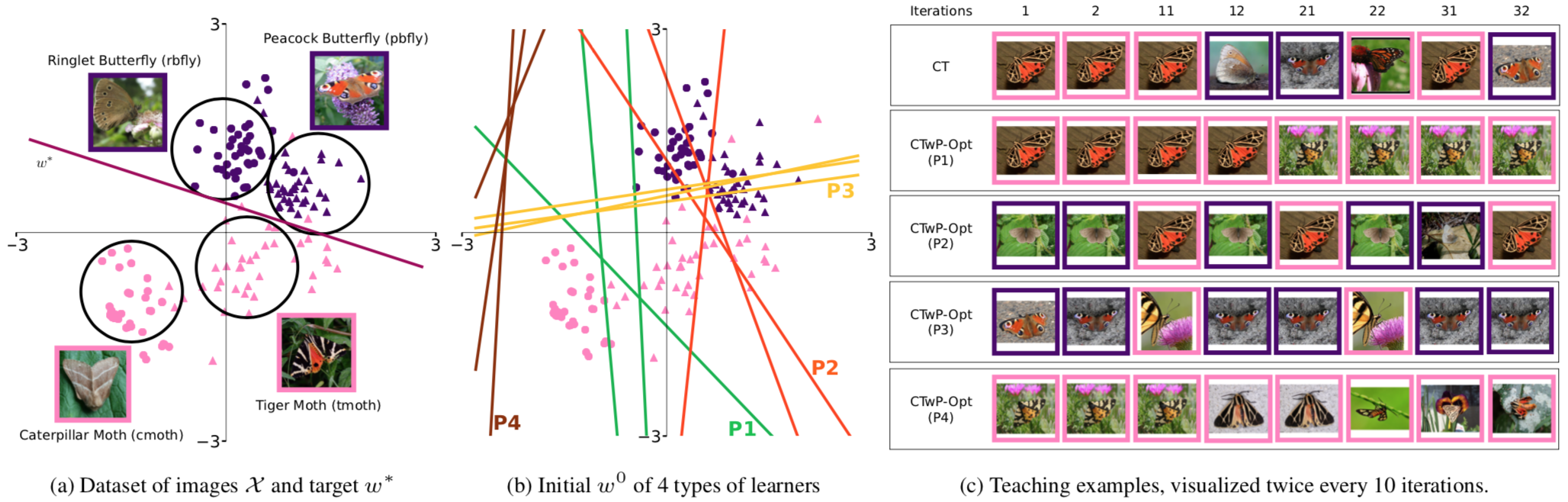
We conduct an experiment on real-world data to demonstrate the usefulness of our teaching paradigm on a binary classification task. Our data consists of 160 images (40 each) of four species of insects, namely (i) Caterpillar Moth, (ii) Tiger Moth, (iii) Ringlet Butterfly, and (iv) Peacock Butterfly. Given an image, the task is to classify it as a butterfly or a moth. Figure 1(a) below, represents a low dimensional embedding of the data set and the optimal separating hyperplane (target concept).
Figure 2: Classifying Butterflies and Moths
We also have initial hypotheses (internal states) of 67 actual human learners for this classification task from Amazon Mechanical Turk workers. These learners represent our classroom. Conceptually, we identify four different types of students based on their internal states as shown by the four different coloured lines. For instance, the group P1 (green) represents those students that incorrectly classify Tiger Moths as butterflies, but can accurately classify the other three species. Similarly, P4 comprises of students who classified every image as a butterfly. What P1 needs are examples of Tiger Moths so they can learn to identify them as moths and not butterflies. Showing them examples of (say) Ringlet Butterflies adds unnecessary effort since they can already identify them correctly.
Figure 3(c) illustrates these ideas more concretely. It depicts thumbnails of training examples generated by our algorithm for the entire classroom (CT) as well as for each group in the the partitioned classroom. Without specific context of butterflies and moths, the algorithm intelligently chooses Tiger Moths examples only for P1, and Tiger and Caterpillar Moth examples alternately for P4. This allows for efficient teaching of the target concept and a good balance between teacher effort and student workload. In the paper, we also demonstrate the performance of the algorithms on simulated data.
Conclusion
Our work reveals the potential of machine teaching for online learning. We achieve small training sample complexity that is an exponential improvement on the standard individual teaching strategy. And we show the applicability of our model in generating interpretable training examples in real-world situations.
For further details about our models, algorithms and experiments, please check out our full paper that has been accepted to AAAI 2019. For questions and comments about the work, please feel free to drop an email to me (Arpit Merchant) at arpitdm [at] gmail [dot] com.
In order to help plan better, work in a more structured fashion and have a record of the work we did during the GSoC 2016 in Sage, we maintained a daily project log. This was institutionalised starting with Week 4 and we reproduce the log below.
Week 12:
16th, 17th August:
Made all the remaining changes, and pushed the changes to the Gabidulin Ticket. Added the code to the catalog files. There are a couple of issues that need to be resolved based on feedback and then the changes can be made. Commit can be found here.
Started writing documentation for the ARMC class. Will push everything I have on that on 18th.
Created three new tickets for the stuff left over from the original 13215 ticket and pushed all the relevant code.
Started preparing presentation for Sage Days 75. Will share the first draft of outline and ideas on 18th.
15th August:
Finished writing documentation and tests for #20970. Finished channel class for the code. After one final pass, will push everything on 16th. There are two tiny issues. One is given a matrix in Sage, how to find a specific non-trivial solution for it. I.e. for matrix A, find non-trivial x_0 s.t. A*x_0 = 0. Currently, the parity evaluation points method is failing because of this. This also causes the channel to fail at times. And the second is suggestions for better names in a couple of places.
Created the second ticket from the leftover stuff from #13215. Will push karatsuba and centering tickets on 16th and the last one as well if possible. Otherwise, this will be done by 17th.
Updates to the ARMC class. Specifically, adding documentation and tests, and fixing some bugs that were causing incompatibility issues with the Gabidulin Code class.
11th, 12th August:
Made changes to 21131. It is open for review.
Made changes to finite field ticket. It is open for review. 21088
Solved some pickling errors and other comments by Travis. The remaining ones are due to Frobenius it seems. Once it’s decided, whether or not to add experimental decorator, I will update it. Almost open for review.
Gabidulin, channel class ready. After one final pass, that ticket will be ready to be done.
Prepared Tickets C and D. Will create them and push after one final pass.
Weight enumerator and additional methods in ARMC.
9th, 10th August:
Created rank_metric.py. Deleted methods according to discussions based on recommended schema. Verified docstrings of inherited methods. Worked on rank support and weight enumerator. Started testing a little. Stuff is not working correctly. Hence the delay in pushing.
Gabidulin inherits from this. Removed rank related methods from there. Made that compatible with this.
21088 – finite fields ticket. nearly done. Will push that tomorrow.
Made changes to 21131 as per discussion
Created Ticket C (karatsuba stuff).
Week 11:
8th August:
Further fixes to 13215. (1.5 hrs)
Worked on the channel class. But in order to use that in the way David mentioned, I need random element. So I figured it would be better to have a few methods of the ARMC class implemented first. Added new file, inherits from ALC. Basic getter methods, moved matrix to vector and vice versa from Gab. Random element. And Gab inherits from ARMC. (6hrs)
Worked on the 21131 ticket. That’s now open for review. (4hrs)
4th August:
Wrote channel class for Gabidulin code. Testing continued. Added some checks. Started adding final documentation for every method. (~5hrs)
Moved MPE to skew poly. Continued with MVP and interpolation based on comments on trac. (~2.5hrs)
3rd August:
Made changes based on comments by Jeroen on Ticket #13215 (~4.5hrs)
Fixed Gao Decoder. Edited the construction of Gabidulin Codes to include twist homomorphism. (~3hrs)
Made changes to #21131 based on latest comments. (~2hrs)
Week 10:
28th, 29th July:
Worked on Ticket #21088. Commits can be found here.
Worked on Ticket #21131. Commits can be found here.
27th July:
Worked on the comments and discussions on Ticket 13215. (~6hrs)
Rewrote and am testing ticket 21088. (~2hrs)
26th July:
Fixed documentation build errors from 13215. (~3hrs)
Added documentation for interpolation, MSP and MPE. Added documentation for Gao decoder in Gabidulin Codes. (~1.5hrs)
Worked on additional polishing of Ticket 13215 based these comments. (~3hrs)
25th July:
Resolved single and double backtick inconsistencies from the various files of ticket 13215. Replaced method _cmp_ with _richcmp_ based on recommendations from mentors. removed some latex imports. Commits can be found here. (~3hrs)
Worked on adding minimum subspace polynomial, multi-point evaluation and interpolation methods for Ticket 21088. Fixed the various bugs and incompatibility errors. Commit can be found here. (~4hrs)
Added documentation and tests for the Gabidulin Code class. Will proceed with the verification of Gao decoder implementation once MPE, MSP and Interpolation are resolved. (~1hr)
Week 9:
20th, 21st, 22nd July:
Several threads of discussion regarding the Ticket A were discussed and worked upon. These changes which included removing double imports and unused classes and methods, adding a section in the index file for documentation, improved module description and definition, across various files and finally documentation, tests and code clean up. The commits can be found here.
Created ticket B based on past discussions and pushed changes. Added documentation, tests, fixed doctests and removed unused methods. The ticket can be found here.
Worked on the Gao Formulation decoder for the Gabidulin Code class.
19th July:
Noted down comments from the review of Ticket #13215 and implemented most of the changes. Once the doubts are clarified tomorrow, I’ll submit the edits. (~4hrs)
Started working on Ticket B and comparing with its “polynomial” equivalent to identify the problem areas. (~2hrs)
18th July:
Fixed final documentation, tests and errors. Cleaned up code and pushed changes. (~5hrs)
Edited Gabidulin Codes to adapt to the updated 13215 ticket. Pending: edit minimum subspace polynomial and multi-point evaluation.(~2hrs)
Started preparing creation of Ticket B. (~1hr)
Week 8:
16th July:
Picked up from the pending work from Friday (yesterday). Added all remaining documentation to the skew_polynomial_element.pyx file. Added all missing tests. (~2.5hrs)
Fixed errors in implementation of a couple of methods (is_gen, section). (0.5hrs) Phased out side from the _pow_ function. (~1hr)
Added small tests and fixes to skew_polynomial_ring_constructor.py. (~1hr) [Only documentation and a couple of tiny methods remain to be added for the Class SkewPolynomialRing_general. Should not take more than an hour or two. Will try and finish this on Sunday. If not, first thing on Monday.]
15th July:
Went through the skew_polynomial_element.pyx, skew_polynomial_ring.py and skew_polynomial_ring_constructor.py file to identify the remaining tasks so as to reach the “needs review” state. (~2hrs)
Added missing methods in skew_polynomial_element.pyx based on discussions. (~2hrs)
Added documentation for some private methods. (~1hr)
14th July:
Cleaned up code, refactored and added some tests and documentation in the skew_polynomial_element.pyx file. (~2hrs)
Removed def gcd, xgcd, quo_rem and monic. Renamed lgcd as left_gcd and respectively for all other methods. (~2hrs)
Phased out “side” arguments. (~1hr)
Solved some bugs that had come up because of the edits and deletions made above. (~1hr)
Went through “polynomial_element.pyx” to compare which methods were missing in the skew_polynomial_element.pyx file. Added some. (~2hrs)
13th July:
Cleaned up, refactored and added some tests and documentation in the skew_polynomial_element.pyx file. (~2hrs)
Implemented a special case of the is_unit method for skew polynomials. General case requires support for finding the order of automorphisms. (~1hr)
Fixed the final remaining doctests. (~1hr)
Finished setting up Sage in Emacs and Sage Notebook. Learning how to use them… (~2hrs)
Started phasing out side.py in 13215. (~1hr)
12th July:
Sorted out cherry pick and pushed changes here. (~1hr)
Decided on the most primary cuts to form Ticket A (as per discussions). Pushed changes here. Other files such as side.py are kept for now and will be phased out during refactoring.(~2hrs)
Fixed NotImplementedError and other standalone failing doctests from skew_polynomial_element.pyx. See commit here. 127 doctests remain. All of them are caused by some invalid homomorphism problem. Started looking into that. (~3.5hr)
Started setting up sage-mode in Emacs and started acquainting myself with it. (~1hr) Cleaning up skew_polynomial_element.pyx. (~1 hr)
11th July:
Prepared notes on the five-way split of the original 13215 ticket and discussed with mentors. (~3hrs)
Set up sage notebook. It was giving some error with openssl and required it to be switched off. (~1hr)
Using cherry-pick to add commits from public branch test_13215_interactive (not merging properly. it is giving some weird error with the test.sheet file. (~1hr) Running doctests on skew_polynomial_element file after the aforementioned commits gives 334 errors. Fixed some very simple basic ones just to see how I can proceed here. (~1hr).
Started cutting away portions of 13215_original to form Ticket A. (~2 hrs)
10th July:
Got an overview of the classes of the ticket and the dependencies between them.
Noted down purpose of each. (~2hrs)
Wrote down observations about what seems redundant and what needs work in every class. Also made a list of all the classes and methods and functions that have missing docstrings and doctests. (~2.5hrs)
Started adding the missing tests and docs for the skew_polynomial_ring.py file. (~1hr)
Week 7:
9th July:
Made final edits to the rank-metric conversion and properties. Wrote documentation and tests. Pushed commit here. (~1.5 hr)
Removed some of the compile errors from the unencode_nocheck method and supporting methods. Finished writing multi_point_evaluation method. I was using the zero element of Fqm to initialize while I was actually supposed to use the zero element of the message_space (skew polynomial ring). Apart from the main error in #13215, the rest of these methods seem to have no errors. Will confirm once resolved. Pushed commit here (~3 hrs)
Made final edits to the documentation and tests of the skew_polynomial_ring_constructor.py file from #13215. Ready to commit. (~1 hr)
8th July:
Edited gabidulin.py based on comments.
Continued writing interpolation of skew_polynomials.
7th July:
Fixed one more of the two remaining errors in #13215. It seems that the ‘Left’ object has not been implemented in a lot of places in the skew polynomial ticket.
Completed reading relevant sections of the paper mentioned below. Started writing code. Placing it in gabidulin.py for now.
6th July:
Wrote conversion for matrix form back into vector form. Added support for computing rank-distance, rank-weight.
Started reading this for how to interpolate a skew polynomial for the unencode and (future) decode methods.
5th July:
Fixed the tiny compile errors that were induced in the Skew Poly ticket due to Sage upgrade.
Testing of code that was written last Friday and Monday that had gone unchecked. Fixed errors.
Wrote conversion into matrix form from vector form of a Gabidulin codeword. Takes a basis as argument.
4th July:
Added support for generator matrix, dual code and parity check matrix of Gabidulin Code.
Week 6:
1st July:
Continued porting to inheritance from SageObject.
30th June:
Fixed bugs in the evaluation_points, encode, message_space and operator evaluation method for skew polynomials (this bit still needs more work).
Based on discussions, removed inheritance of Gabidulin Code class from AbstractLinearCode class. Now moving towards a stand-alone class that inherits from SageObject.
29th June:
Added support for the default option from below.
Created a method for the “ext” function from Lemma 2.1 (of the PhD thesis) on Mapping to Ground Field.
28th June:
Started adding some tests for the various methods.
Added support for an optional argument that can be supplied to the constructor for the code. This allows them to provide a set of linearly independent elements of F_{q^m} over F_q if they choose. Need to add support for default option.
27th June:
Continued working on constructing a codeword.
Trying different input arguments to see which is most convenient to use and still allows flexibility for user.
Week 5:
24th June:
Evaluated linearized polynomials (sample examples) at various random points.
Called relative finite field extension ticket for the vectorial representation of big field in small field in an attempt to form a codeword. This is not working properly. But I think I should have something to present on Monday.
23rd June:
Tested construction of linearized polynomials from skew polynomials. By putting in a zero derivation and a Frobenius endomorphism (for a finite field, Frobenius endomorphism is a Frobenius automorphism and hence this is a linearized polynomial ring), it seems to be constructing a ring. Will have to test addition and multiplication once the doctests are solved.
22nd June:
Submitted Midterm Evaluation. Prepared blog post. Nearly ready to put it up.
Continued to fix errors. And pushed recent commits to Ticket 13215. Down to final 2 types of errors.
19th June:
Caught a bug. Came down with a flu. Stuck in bed all day.
Week 4:
17th June:
Continued fixing doctest errors. Relatively slow day, managed to get about 70 solved today. Still about 330 to go. Starting to get the hang of this now. I think.
Started drawing up design document for Gabidulin codes. The aim is to try and get all the errors resolved by this weekend and scrub the patch and get it accepted by Monday.
16th June:
Continued fixing doctest errors. Managed to get about 200 solved today. Still 400 to go.
15th June:
Continued fixing doctest errors in the Skew Polynomial patch. Reported no_attribute_found errors in richcmp, init_cache, and other ValueErrors.
Read the Skew Polynomials patch to try and understand what can be used and how for the construction of Gabidulin codes.
14th June:
Began fixing doctest errors in the Skew Polynomial patch. There were about 650 errors to begin with.
Solved some very simple errors such as Deprecation warnings, errors with “interrupt.pxi” etc. About 600 more to go.
This document is meant to be a reference for people who want to understand the work done on implementing Skew Polynomials and Rank Metric Codes in Sage as a part of this GSoC 2016 project. My mentors for this project are Johan Rosenkilde and David Lucas. This post provides a brief mathematical background, summary and status of the tickets related to the project and further links to detailed discussions and the code. It is assumed that the reader is familiar with the basic concepts of abstract algebra, coding theory and Sage itself.
Background:
A Skew Polynomial is given by the equation:
where the coefficients and is a formal variable. Let be a commutative ring equipped with an automorphism . Addition between two skew polynomials is defined by the usual addition operation and the modified multiplication is defined by the rule for all in . Skew polynomials are thus non-commutative and the degree of a product is equal to the sum of the degrees of the factors. Then the ring of skew polynomials can be written as .
Linear Rank Metric Codes are linear error correcting codes over the rank-metric and not the Hamming metric. The distance between two matrices is defined as the rank of the difference between them. And this forms a metric. They are a way to build codes that can detect and correct multiple random rank errors. Gabidulin Codes are an example of linear rank metric codes.
A Gabidulin Code over of length (at most ) and dimension (at most ) is the set of all codewords, that are the evaluation of a skew polynomial belonging to the skew polynomial constructed over the base ring and the twisting automorphism .
where the fixed evaluation points are linearly independent over . These codes are the rank-metric equivalent of Reed Solomon Codes.
Implementation:
During the community bonding period, we started with a small fix to the wtdist_gap method from the module linear_code.py. This involved improving its documentation, changing to a better name and making the method private. We also opened a ticket for a new abstract class for Golay Codes. However, there was not enough time to finish this ticket since the coding period started.
David had already implemented a class to manage representation of elements of a field extension into a smaller field. We went through the review checklist in Sage. This has now been merged into Sage.
Xavier Caruso had authored a ticket on Skew Polynomials about four years ago. This was not reviewed at the time. And the category framework in Sage underwent massive restructuring and change since then. As a result, this ticket was very incompatible. We first started by resolving the several hundred doctest errors some of which were due to deprecated syntax errors while others were more technical. This ticket was the most difficult and complicated module and it took a lot longer than originally anticipated. Debugging the code ended up breaking Sage several times before all originally present doctest errors were resolved. Once the ticket started working, a lot of the methods and classes still did not have proper documentation and/or tests and we added those. Since this was a huge ticket, we then decided to break it up into five smaller tickets based on the content and dependencies to make the work more manageable. We majorly refactored the code in the first ticket to make it cleaner and then added methods such as operator evaluation, interpolation, minimum vanishing polynomial, etc to the appropriate various classes. For the purposes of the other targets for the GSoC project, we practically needed only the first of the five tickets (mentioned above) which dealt with the basic implementation of skew polynomials and skew polynomial rings. So the primary focus has been to get that merged. The second ticket based on skew polynomials over finite fields has also been worked upon. The remaining three tickets were more or less lifted directly from the original skew polynomial ticket and no effort has been made yet to accommodate for changes to these.
We then created a new abstract base class for Gabidulin Codes and implemented Generator Matrix based and Skew Polynomial Evaluation based encoders for it. This module also included a Gao Decoder for the Gabidulin Code and a Channel class to introduce random rank errors. Along with all of this, basic getter methods and methods to compute some basic combinatorial properties were also implemented.
Lastly, we worked on a new base class called AbstractLinearRankMetricCode that inherits from the AbstractLinearCode class and from which Gabidulin Code inherits. This class provides methods that are common to any Linear Rank Metric Code so as to facilitate the creation of other such codes. It also deletes those methods from the general linear code class that are not valid in the case of rank metric codes.
Current Status: The tickets related to skew polynomials, Gabidulin Codes and AbstractLinearRankMetricCode are currently still open. We believe that the skew polynomial ticket is almost ready to be merged into Sage. It has been well tested and we believe it is in stable condition. The Gabidulin Code ticket is not as rigorously tested and the Gao decoder in particular needs to be examined further. The completion of this ticket depends on the AbstractLinearRankMetricCode class which requires also requires some work.
I am currently attending Sage Days 75 in Paris to which I was invited by my mentors. We have coding sprints all week long and we aim to wrap up all of the starred tickets (see below) this week. The next section provides links to more elaborate details about the work done during the project.
Code:
All relevant tickets, bug reports and code commits can be found below:
Gabidulin Codes, one of the primary modules of my GSoC project, are Maximum Rank Distance (MRD) codes analogous to Reed Solomon in Rank-Metric. In this post, I give a basic overview of the one of the preliminaries, Skew and Linearized Polynomials, required in their construction in Sage.
Consider a non-commutative ring where we have a ring A of usual polynomials in variable X, a ring endomorphism on A and a -derivation which is essentially a map such that for all a, b in A,
This ring with the usual addition and modified multiplication subject to the relation above is called a Skew Polynomial Ring of Endomorphism type. Recall that, a Homomorphism is a structure preserving map from one mathematical object (such as group, ring, vector space) to another. And an Endomorphism is a homomorphism from a mathematical object onto itself.
Given a finite field of order q and its extension field for some fixed positive integer m, a Linearized Polynomial in variable X is given by
where each of the coefficients belongs to and the exponents of the monomials are powers of q. The degree of this polynomial, also called the q-degree, is n-1. The non-commutative univariate Linearized Polynomial Ring consisting of all such polynomials L(X) over is denoted by . Ernst Gabidulin used this ring to build Gabidulin codes where codewords are given by the coefficients of the polynomials, i.e. .
Linearized and Skew Polynomial Rings are isomorphic with matching evaluation maps. More specifically, when the derivation is 0 and the endomorphism is a Frobenius Automorphism (recall that an automorphism is an endomorphism that admits an inverse and for a finite field, a Frobenius Endomorphism is always also a Frobenius Automorphism), the Skew Polynomial Ring becomes a Linearized Polynomial Ring. That is to say, the latter are a special case of the former.
Sage has an open ticket that already implements the Skew Polynomial Ring and provides functionality to evaluate a given polynomial and perform basic operations such as addition, subtraction, multiplication and division. Our aim therefore, is to complete the open ticket and use that to create the appropriate, required linearized polynomial ring.
Setting up for developing Sage is one thing, actually contributing to the development is a completely different ball game. The development process, broadly speaking, consists of the following steps:
Identify a defect, bug, enhancement or new feature that Sage has or requires.
Open a ticket on Trac describing the exact problem.
Enter discussions with other community members on clarifying the issue and discuss solution and implementation ideas.
Write code and submit.
Get it reviewed by other at least one other independent programmer.
If review is positive, the ticket is closed and code is successfully merged. Otherwise, go back to step 3 and repeat.
As a contributor, one needs to know how to do both, review as well as successfully write code. And that is what this post describes. I’ll use tickets that I worked on, to illustrate these aspects of development in further detail. In order to avoid confusion, I’ll use Code while talking about Coding Theory and code to talk about programming.
Reviewing a Ticket:
David and Johan (my mentors for the project) suggested Ticket #20113. The zero method in the linear_code.py file was supposed to return the zero vector of the associated Code. The original implementation called the gens method (the generators of the Code), took the first element of the returned list, multiplied it by 0. This resulted in all zero vector of length of the Code. While the solution wasn’t incorrect, this was a rather tedious way of obtaining it. David had already submitted a patch that simply called the zero element from the ambient space of the Code to produce the answer.
My job was to review this new code and at first glance, this seems trivially correct. And it was. But this may not always be the case. Sage is a massive beast and a small change in one part of the code could break something in some other seemingly unrelated part of the code. There are a lot of things that need to be verified and the best way is to simply follow the Reviewer’s Checklist. I’ll clarify some of the terms from there first and then provide a general rule-of-thumb workflow on how to interact with the git-trac system to review.
Doctests and Coverage: The documentation for each of the methods in Sage contains examples of code that explains how to use the method. Python can search for and extract these commands, run them and compare the output to the one mentioned in the documentation. If the patch changes code, the doctests for all the changed methods must still hold true. To do this, run the command `./sage --coverage src/sage/coding/linear_code.py.
Manuals and Building: Manuals serve as a reference book and can be incredibly useful for quick reference. Sage adds material to its manuals from the documentation in the source code itself. Which is why the documentation should follow a specific template. See here for examples and notice the formatting and indentation. Run `./sage –docbuild reference html` to build the html version of the “Reference” Manual. Others include _tutorial, developer, constructions and installation_. These are also available in pdf versions.
Speedup: Generally, it is hard to check the speed. Standard Python time-management (import time, time_clock()) can be used. The main idea is to ensure that the new code does not utterly slow down Sage. Patchbot reports can also be used but caution should be exercised and error reports should be double-checked. Run methods on large inputs, compare to other softwares that offer similar functionality, try boundary cases and consistency checks based on mathematical foundations.
Review Workflow:
git trac checkout TICKET_NUM (This will create a local branch say t/20113)
git checkout t/20113
./sage -b (See if the code builds without errors)
Run through the Checklist above and note down errors, if any.
Run various test examples in an attempt to “break” the code.
Go to Trac and write comment(s).
Change ticket status.
Write your full name in the Reviewer field of the ticket.
Writing a Ticket:
David and Johan suggested improving the efficiency of the decode_to_code method of the Nearest Neighbour Decoder. I opened a Ticket #20201 on Sage to fix this. The previous implementation created and stored the distances between the received word and every codeword. It then sorted the entire list in order to find the closest codeword. This took exponential memory and time in the size of the Code which can be very inefficient for large input. An obvious solution is to compute the Hamming weight for the first codeword and set that as the minimum. Then, iterating over the rest of the codewords and updating the minimum drastically brings down the memory and run time requirements.
There are some major differences when it comes to actually opening a new ticket and writing code for it. Whenever you write new code in Sage, you might want to add some print statements and code, run the files, test, make small changes and test again. In that case, you have to build sage (./sage -b) or in some cases even run make distclean && make which can take a very long time. Instead, the best way is to write your new code in a myfile.sage file and then run ./sage myfile.sage.
Write Workflow:
Open a new ticket on Sage. Or if a ticket that has commits already exists, create a local branch on your system. And then pull the changes from the ticket onto your branch. Do not directly checkout the ticket. It can result in very weird errors.
Discuss solution idea on trac.
On the local branch (NOT master) corresponding to the ticket, write your code.
Test your code.
git add <changed_file(s)>
git commit -m "insert detailed message here."
`git trac push TICKET_NUM`
Once you’re satisfied with your commits, set the ticket field to “needs_review”.
If positive, ticket closed. Else, go back to step 2.
As a final note, Sage is guaranteed to break down at any point for seemingly no valid, discernible reason and I’ve lost track of the time I’ve spent in trying to fix it. But in doing so, I’ve learnt a lot about the codebase and once you successfully manage to rebuild Sage, there is a weirdly awesome feeling of accomplishment!
Sage is a viable open source mathematics software package that offers an extensive toolbox
for algebra, combinatorics and numerical computations. This massive project can seem daunting to someone who wants to begin contributing to it, especially in the short GSoC application period. In what follows, I cover a constantly updating collection of advice for new programmers, to simplify the process of applying to Sage.
sage-gsoc – related discussions regarding the GSoC program
Apart from these, there are tons of other topic based lists dedicated to specific modules. For example, sage-coding-theory. When applying to GSoC, find a project from the Ideas page and post on sage-gsoc (with a cross post on the related topic-based list, if it exists) indicating your interest in the project and request more details; instead of simply asking for help in “getting started” since one is “very interested in contributing to open source”.
Source Code:
Source Code – Download your copy of Sage from here
git.sagemath.org – Online Sage repository. A good way to read the code online
Trac – Organizing development and code review through tickets
2) Contributing to Sage
The following is more of a cheat sheet to setup everything you need so you can begin contributing. When in doubt or need of further clarity, always refer to the official documentation. It is really well written!
Installation:
Install Sage: Assuming the source code is downloaded, unzip it and go inside the directory. And run “make”. This should take a few hours. Once it finishes, you can run it by typing “./sage” on the command prompt.
Configure git: Assuming you have git installed, run the following two configuration commands (if you haven’t already)
Install git-trac:Now, all development tasks can be performed in the usual way using git and a browser. Alternatively git-trac can simplify the communication process between git and trac. To use this, run:
Obtain Sage Trac account: Development happens through tickets on Trac. In order to comment, review, commit or interact in any other active way with the source code, a Trac account is required. To do that, send an email to sage-trac-account@googlegroups.com, containing your full name, preferred username, contact email and reason for needing an account. Once the request is approved, a username and password will be assigned.
Configure git-trac: Authentication mechanism is required for read-write access. Simply put, sage needs to be told about trac with verification. To do this, run:
Run the Sage prompt (./sage) and upload it to trac using the command “dev.upload_ssh_key()“. Use the credentials obtained above for completing the authentication.
Again, the Sage documentation is magnificent and it should be referred to in case of doubts or further explanations. Once all this is done, one can start contributing by checking out an existing ticket or opening a new one. There is a lovely cheat sheet on how to do all that, already available. The way development happens is, someone opens a ticket regarding a bug, defect, new feature or enhancement and writes code for it. Once the commit is ready, it is opened for review whereupon an independent second programmer checks it and suggests changes or gives it a thumbs up.
Communicating with the Sage community:
While the people in the community are extremely helpful, it is necessary to ask for help wisely. Through the communications, three aims need to be achieved:
Form a positive impression on the mentors and admins: Ask precise questions (and don’t hesitate to ask them), ask for help if you don’t understand something but do your homework before asking. For instance, I was asked to review a tiny patch and I didn’t know what review entailed. Sage documentation has a Reviewer’s Checklist and I tried to follow that and asked questions when I didn’t understand something from there.
Make a small contribution(s) to the code: Ask for tickets related to the project you are applying for since that will not only help you understand the development process better, but also the module itself. Ideally, I’ve found that a review of one ticket and writing another new ticket on an associated module can suffice.
Understand and further define the project: Mentors have usually given the project more thought and therefore it is a good idea to talk to them and get an idea about what they have in mind for it first. What is not available, is an exact statement on what all needs to be added and how. Ask for reading material, get clarity on the various modules that need to be implemented as part of the project and come up with a plan on what needs to be done to achieve that.
3) Writing a GSoC Proposal
A good proposal cannot be prepared without a proper understanding of the organization and the project idea itself. And simply having a good understanding is not enough, if that is not visible through the proposal. There is no right way of preparing a proposal. The best way is to go over as many of them as you can find and then suitably adapting elements from each to suit the particular project in question. Here’s mine for what it’s worth: Rank-Metric Codes in Sage
There’s plenty of other advice on how to write a good proposal available; the recurring points being concise writing, clarity on project deliverables, structured timeline and review from mentors.

 and
and  is a formal variable. Let
is a formal variable. Let  be a commutative ring equipped with an automorphism
be a commutative ring equipped with an automorphism  . Addition between two skew polynomials is defined by the usual addition operation and the modified multiplication is defined by the rule
. Addition between two skew polynomials is defined by the usual addition operation and the modified multiplication is defined by the rule  for all
for all  in
in ![R[X, \sigma]](https://s0.wp.com/latex.php?latex=R%5BX%2C+%5Csigma%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.![Gab[n, k]](https://s0.wp.com/latex.php?latex=Gab%5Bn%2C+k%5D&bg=ffffff&fg=000000&s=0&c=20201002) over
over  of length
of length  (at most
(at most  ) and dimension
) and dimension  (at most
(at most  belonging to the skew polynomial constructed over the base ring
belonging to the skew polynomial constructed over the base ring ![\text{Gab[n, k]} = \big\{ (f(g_0) f(g_1) ... f(g_{n-1})) = f(\textbf{g}) : \text{deg}(f(x)) < k \big\}](https://s0.wp.com/latex.php?latex=%5Ctext%7BGab%5Bn%2C+k%5D%7D+%3D+%5Cbig%5C%7B+%28f%28g_0%29+f%28g_1%29+...+f%28g_%7Bn-1%7D%29%29+%3D+f%28%5Ctextbf%7Bg%7D%29+%3A+%5Ctext%7Bdeg%7D%28f%28x%29%29+%3C+k+%5Cbig%5C%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
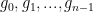 are linearly independent over
are linearly independent over 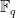 . These codes are the rank-metric equivalent of Reed Solomon Codes.
. These codes are the rank-metric equivalent of Reed Solomon Codes.![{R = \mathbb{F}[X; \sigma, \delta]}](https://s0.wp.com/latex.php?latex=%7BR+%3D+%5Cmathbb%7BF%7D%5BX%3B+%5Csigma%2C+%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) where we have a ring A of usual polynomials in variable X, a ring endomorphism
where we have a ring A of usual polynomials in variable X, a ring endomorphism  on A and a
on A and a  -derivation which is essentially a map
-derivation which is essentially a map  such that for all a, b in A,
such that for all a, b in A,

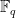 of order q and its extension field
of order q and its extension field  for some fixed positive integer m, a Linearized Polynomial in variable X is given by
for some fixed positive integer m, a Linearized Polynomial in variable X is given by
 belongs to
belongs to ![{\mathbb{L}_{q^m}}[X]](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BL%7D_%7Bq%5Em%7D%7D%5BX%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Ernst Gabidulin used this ring to build Gabidulin codes where codewords are given by the coefficients of the polynomials, i.e.
. Ernst Gabidulin used this ring to build Gabidulin codes where codewords are given by the coefficients of the polynomials, i.e. 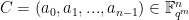 .
.