This post summarizes our paper which will be presented at the 33rd AAAI Conference on Artificial Intelligence (AAAI-2019).
Introduction
I was fascinated by the idea behind Machine Teaching ever since I was introduced to it in The Teaching Dimension of Linear Learners (JMLR-2016) by Liu, et al. Machine teaching is the inverse problem of machine learning. In machine learning, we are given a set of training examples and the goal is to design a model that accurately “learns” the target concept. In machine teaching, the objective is to design an optimal set of training examples (e.g. smallest size) to accurately “teach” the target concept to a given learning model.
Our paper takes inspiration from two ideas; teaching a single learner in the online setting introduced in Iterative Machine Teaching (ICML-2017) by Liu, et al, and the complexity of simultaneously teaching multiple learners in the offline setting studied in No Learner Left Behind (IJCAI-2017) by Zhu, et al. We focus on simultaneously teaching a classroom of diverse learners in the online setting. More specifically, we (i) design new, state-of-the-art teaching algorithms with provable guarantees under complete and incomplete information paradigms, (ii) discuss classroom partitioning strategies for improved teaching and learning experiences, and (iii) experimentally evaluate the performance of our algorithms on simulated and real-world data.
The Model
Our model consists of the following elements.
- Parameters: The feature space of training examples, the label set (discrete or continuous depending on classification or regression), and the feasible hypothesis space including the target hypothesis comprise our primary parameters.
- Classroom: The classroom is a set of online projected stochastic gradient descent learners. Each learner is defined by two internal parameters, a time-varying learning rate, and a time-varying internal state.
- Teacher: The teacher is characterized by the amount of information she has about the students in the classroom. Knowledge represents information regarding the learning rates of the students and Observability represents information about the internal states.
- Teaching Objective: We consider two objectives, either to ensure that every student in the classroom converges to the target concept or to ensure that the entire classroom on average converges to the target concept, as quickly as possible.
We consider different scenarios wherein the teacher has complete information about all the parameters and perfect Knowledge and Observability, or limited Knowledge and perfect Observability, or perfect Knowledge and limited Observability. In each of the scenarios, the model functions over a series of interactions between the teacher and the classroom. At every interaction (or time-step), the teacher receives updated information about the classroom (as defined by the scenario in question). She then chooses a training example and the corresponding label from the feature space and label set respectively, and provides it to the classroom. Lastly, each student in the classroom performs a gradient update step. This cycle repeats until the teaching objective is achieved.
The core idea of our algorithms is the training example construction step. The trick is to pick that example at every time step which minimizes the average distance between students’ internal states and the target concept. This translates to solving an optimization task. In general, this is a non-convex problem, but in the case of learners following a squared-loss function, we present a closed-form solution. For each of the scenarios, we also provide theoretical guarantees for the number of examples or iterations the teacher requires to teach the target concept.
Classroom Partitioning
Individual teaching, the notion of teaching one student at a time, is extremely useful for the individual student because she receives personalised training. However, it is extremely cumbersome for the teacher because she has to expend extra effort in producing these personalised resources. On the other hand, having a large classroom of diverse students reduces the teacher’s effort while increasing the workload on the students. A well-studied solution from pedagogical research is to partition the classroom into smaller groups. However, there isn’t a consensus on the optimal partitioning strategy.
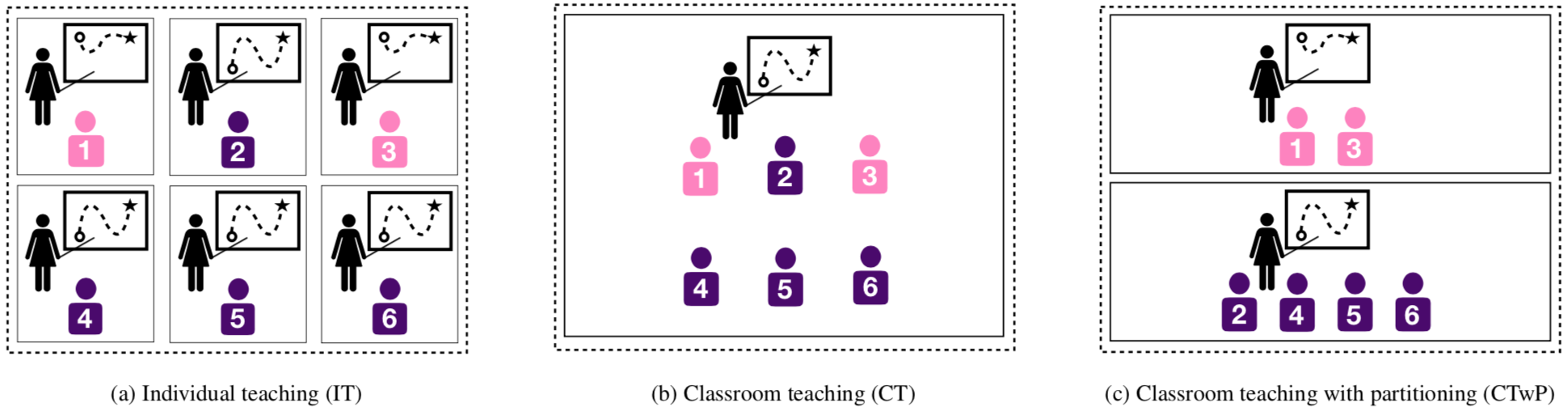
We propose two straightforward strategies for homogenous partitioning that follow from our model setting. The first is grouping based on learning rates of students and the second is group based on internal states. The first idea is helpful because faster learners can quickly converge to the target concept whereas slower learners would require more samples. Placing the fast learner in the same group as a slow learner adds unnecessary extra effort on the fast learner. The second idea is helpful because it groups similar kinds of students together. See the next section for a more concrete example of this.
Experiment: Classifying Butterflies and Moths
We conduct an experiment on real-world data to demonstrate the usefulness of our teaching paradigm on a binary classification task. Our data consists of 160 images (40 each) of four species of insects, namely (i) Caterpillar Moth, (ii) Tiger Moth, (iii) Ringlet Butterfly, and (iv) Peacock Butterfly. Given an image, the task is to classify it as a butterfly or a moth. Figure 1(a) below, represents a low dimensional embedding of the data set and the optimal separating hyperplane (target concept).
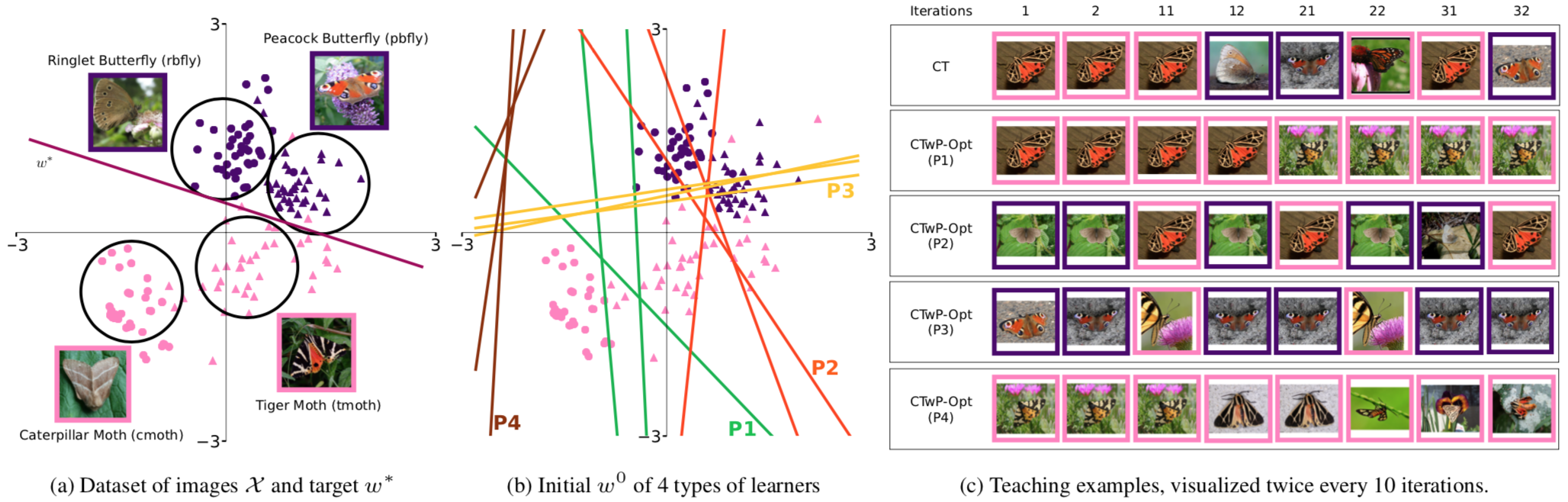
We also have initial hypotheses (internal states) of 67 actual human learners for this classification task from Amazon Mechanical Turk workers. These learners represent our classroom. Conceptually, we identify four different types of students based on their internal states as shown by the four different coloured lines. For instance, the group P1 (green) represents those students that incorrectly classify Tiger Moths as butterflies, but can accurately classify the other three species. Similarly, P4 comprises of students who classified every image as a butterfly. What P1 needs are examples of Tiger Moths so they can learn to identify them as moths and not butterflies. Showing them examples of (say) Ringlet Butterflies adds unnecessary effort since they can already identify them correctly.
Figure 3(c) illustrates these ideas more concretely. It depicts thumbnails of training examples generated by our algorithm for the entire classroom (CT) as well as for each group in the the partitioned classroom. Without specific context of butterflies and moths, the algorithm intelligently chooses Tiger Moths examples only for P1, and Tiger and Caterpillar Moth examples alternately for P4. This allows for efficient teaching of the target concept and a good balance between teacher effort and student workload. In the paper, we also demonstrate the performance of the algorithms on simulated data.
Conclusion
Our work reveals the potential of machine teaching for online learning. We achieve small training sample complexity that is an exponential improvement on the standard individual teaching strategy. And we show the applicability of our model in generating interpretable training examples in real-world situations.
For further details about our models, algorithms and experiments, please check out our full paper that has been accepted to AAAI 2019. For questions and comments about the work, please feel free to drop an email to me (Arpit Merchant) at arpitdm [at] gmail [dot] com.
